文章
NLP(5)——基于依存分析的开放式中文实体关系抽取方法
前言:由于主要是涉及一些NLP的东西,所以将本文放到NLP里面。 前期学习的资料:
前言:由于主要是涉及一些NLP的东西,所以将本文放到NLP里面。 前期学习的资料:
-
pyltp - 哈工大语言云python接口使用说明https://www.jianshu.com/p/867478f0e674
-
基于依存分析的开放式中文实体关系抽取方法,李明耀;百度可以找到
-
郑珊珊 基于中文语法特征的开放领域实体关系抽取
环境安装
安装pyltp 1 用pip 报错的话就把版本修改一下 2 下载版本对应的模型http://ltp.ai/download.html
前人基础
bootstrapping算法实现了半监督远程关系抽取, 算法通过种子模板抽取特征词,利用最近邻原则自动生成更多的抽取模板 但是在扩展的过程 中会加入很多不正确的抽取模板并且使得错误不 断积累影响最终的效果
抽取三元组
过程: 先分词 词性标注 命名实体识别(只能识别人名 地名 机构名)若其他实体需要标记 依存分析 基本如下:
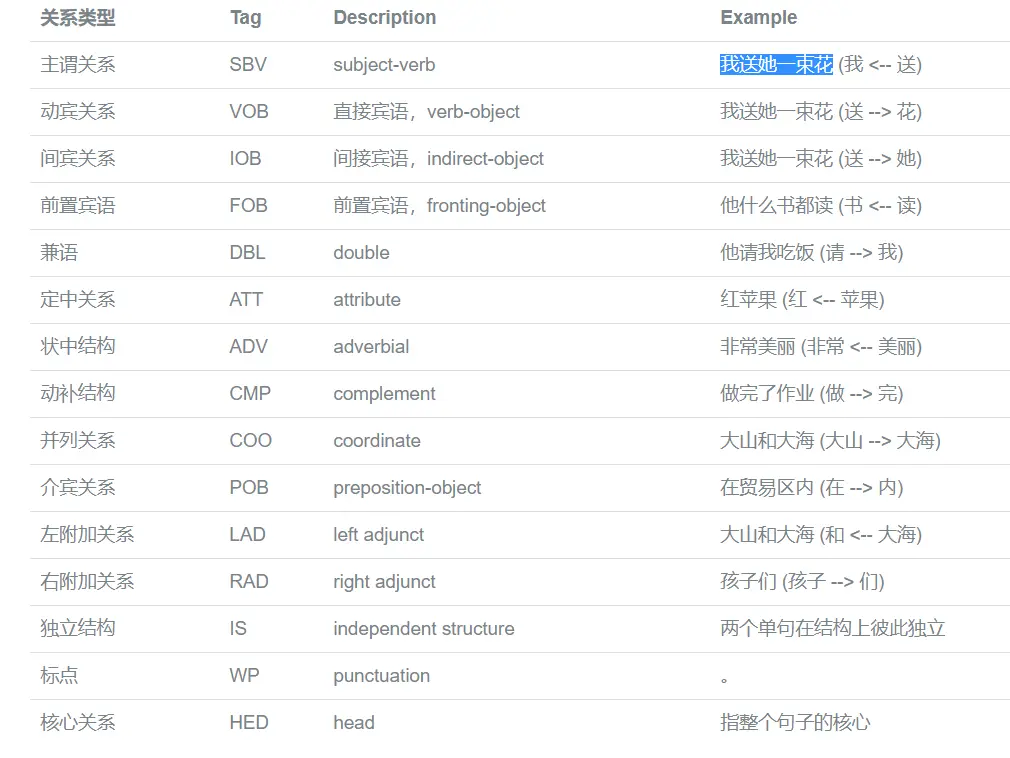
网址:https://www.ltp-cloud.com/intro/#ner_how
代码如下:
工具模型加载:
segmentor = Segmentor()
segmentor.load(os.path.join(MODELDIR, "cws.model"))
postagger = Postagger()
postagger.load(os.path.join(MODELDIR, "pos.model"))
parser = Parser()
parser.load(os.path.join(MODELDIR, "parser.model"))
recognizer = NamedEntityRecognizer()
recognizer.load(os.path.join(MODELDIR, "ner.model"))核心关系抽取如下:
for index in range(len(postags)):
# 抽取以谓词为中心的事实三元组
if postags[index] == 'v':
child_dict = child_dict_list[index]
# 主谓宾
if child_dict.__contains__('SBV') and child_dict.__contains__('VOB'):
e1 = complete_e(words, postags, child_dict_list, child_dict['SBV'][0])
r = words[index]
e2 = complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
out_file.write("主语谓语宾语关系\t(%s, %s, %s)\n" % (e1, r, e2))
print(e1,r,e2)
out_file.flush()
# 定语后置,动宾关系
if arcs[index].relation == 'ATT':
if child_dict.__contains__('VOB'):
e1 = complete_e(words, postags, child_dict_list, arcs[index].head - 1)
r = words[index]
e2 = complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
temp_string = r+e2
if temp_string == e1[:len(temp_string)]:
e1 = e1[len(temp_string):]
if temp_string not in e1:
out_file.write("定语后置动宾关系\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()
# 含有介宾关系的主谓动补关系
if child_dict.__contains__('SBV') and child_dict.__contains__('CMP'):
#e1 = words[child_dict['SBV'][0]]
e1 = complete_e(words, postags, child_dict_list, child_dict['SBV'][0])
cmp_index = child_dict['CMP'][0]
r = words[index] + words[cmp_index]
if child_dict_list[cmp_index].__contains__('POB'):
e2 = complete_e(words, postags, child_dict_list, child_dict_list[cmp_index]['POB'][0])
out_file.write("介宾关系主谓动补\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()
# 尝试抽取命名实体有关的三元组
if netags[index][0] == 'S' or netags[index][0] == 'B':
ni = index
if netags[ni][0] == 'B':
while netags[ni][0] != 'E':
ni += 1
e1 = ''.join(words[index:ni+1])
else:
e1 = words[ni]
if arcs[ni].relation == 'ATT' and postags[arcs[ni].head-1] == 'n' and netags[arcs[ni].head-1] == 'O':
r = complete_e(words, postags, child_dict_list, arcs[ni].head-1)
if e1 in r:
r = r[(r.index(e1)+len(e1)):]
if arcs[arcs[ni].head-1].relation == 'ATT' and netags[arcs[arcs[ni].head-1].head-1] != 'O':
e2 = complete_e(words, postags, child_dict_list, arcs[arcs[ni].head-1].head-1)
mi = arcs[arcs[ni].head-1].head-1
li = mi
if netags[mi][0] == 'B':
while netags[mi][0] != 'E':
mi += 1
e = ''.join(words[li+1:mi+1])
e2 += e
if r in e2:
e2 = e2[(e2.index(r)+len(r)):]
if r+e2 in sentence:
out_file.write("人名//地名//机构\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()