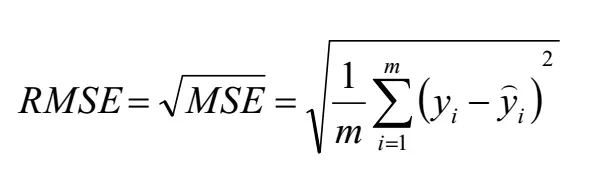文章
机器学习篇(3)——最小二乘法
前言:主要介绍了从最小二乘法以及应用
前言:主要介绍了从最小二乘法以及应用
概念
顾名思义,线性模型就是可以用线性组合进行预测的函数,如图:
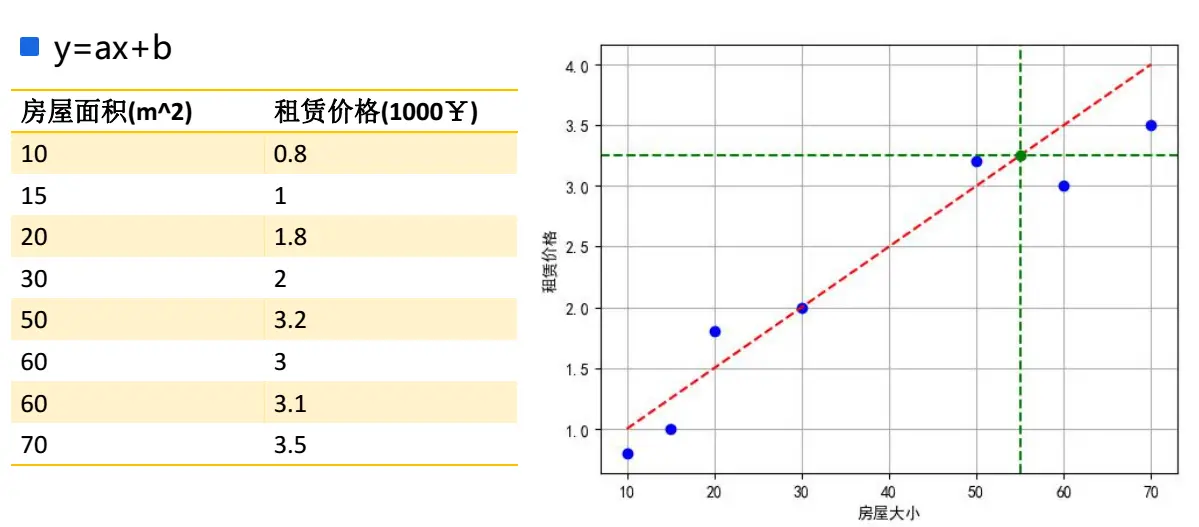
公式如下:
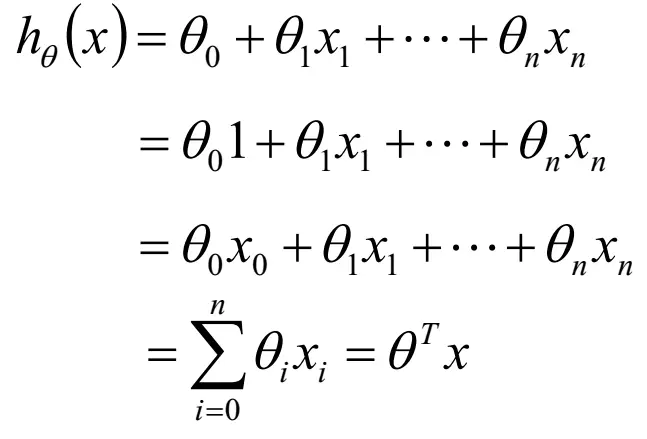
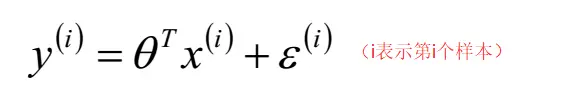
误差是独立同分布的,服从均值为0,方差为某定值s2的高斯分布。
原因:中心极限定理
实际问题中,很多随机现象可以看做众多因素的独立影响的综合反应,往往服从正态分布
写出损失函数:
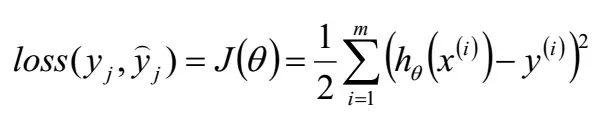
求解:
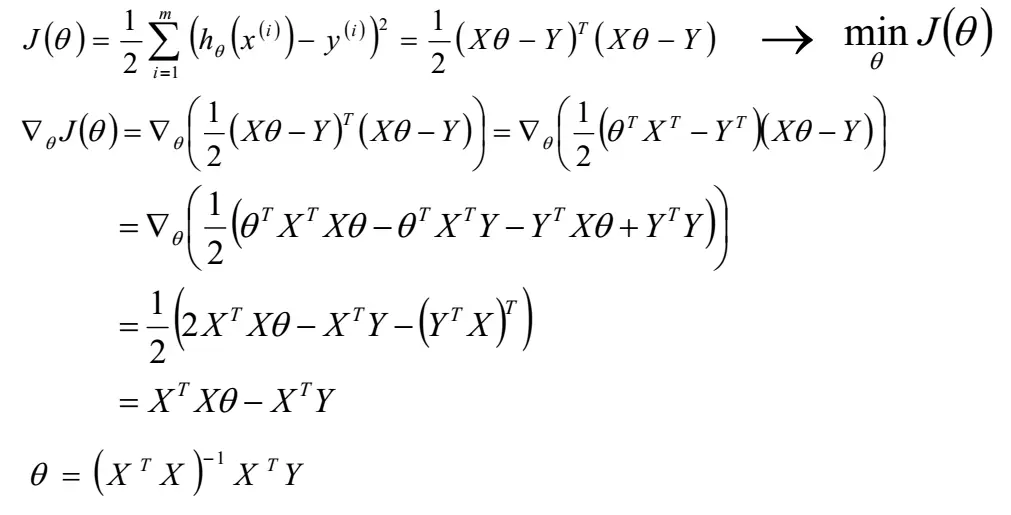
求得的解刚好和线性代数中的解相同
最小二乘法
用投影矩阵可以解决线代中方程组无解的方法就是最小二乘法,其解和上述解一样

例子:用最小二乘法预测家用功率和电流之间的关系
数据来源:http://archive.ics.uci.edu/ml/datasets/Individual+household+electric+power+consumption
代码如下:
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib as mpl
import matplotlib.pyplot as plt
import time
#防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#加载数据
path = "household_power_consumption_1000.txt"
df = pd.read_csv(path,sep=";",low_memory=False)
#功率和电流之间的关系
X = df.iloc[:,2:4]
Y = df.iloc[:,5]
#数据集划分两个参数test_size表示怎么划分,random_state固定随机种子类似于在执行random模块时候,给一个随机种子random.seed(0),之后每次运行的随机数不会改变
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=0)
#转化为矩阵形式,进行最小二乘法运算,即矩阵的运算
x1 = np.mat(x_train)
y1 = np.mat(y_train).reshape(-1,1)#转化为一列-1表示一后面1列为标准
#带入最小二乘公式求θ
theat = (x1.T*x1).I*x1.T*y1
print(theat)
#对测试集进行训练
y_hat = np.mat(x_test)*theat
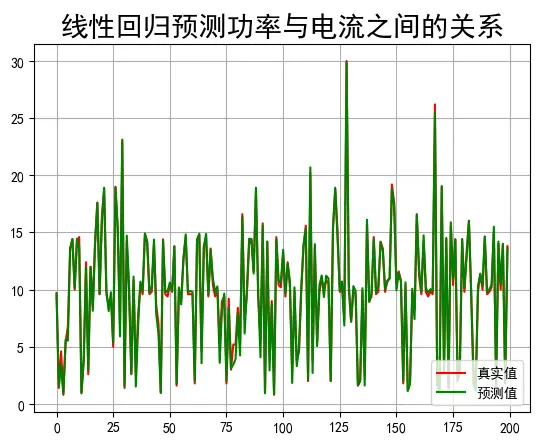
#画图看看,预测值和实际值比较200个预测值之间的比较
t = np.arange(len(x_test))
plt.figure()
plt.plot(t,y_test,"r-",label=u'真实值')
plt.plot(t,y_hat,"g-",label=u'预测值')
# plt.legend(loc = 'lower right')
plt.title(u"线性回归预测功率与电流之间的关系", fontsize=20)
plt.grid(b=True)
plt.show()输出结果:θ=[[4.20324605], [1.36676171]] 预测结果:
其中”from sklearn.model_selection import train_test_split“中的数据划分模块可以用底层代码实现,实现如下:
import random
import csv
def loadDataset(fileName,split,trainingSet=[],textSet=[]):
with open(fileName, "r") as f:
reader = csv.reader(f)
data = list(reader)
for x in range(len(data) - 1):
for y in range(4):
data[x][y] = float(data[x][y])
if random.random()
### 评估指标
- R^2 关于R2的概念,他是衡量数据集是否为线性的依据。叫判定系数、拟合优度,决定系数。 参数解释的原文如下:
> The coefficient R^2 is defined as (1 - u/v), where u is the regression sum of squares ((y_true - y_pred) ** 2).sum() and v is the residual sum of squares ((y_true - y_true.mean()) ** 2).sum().
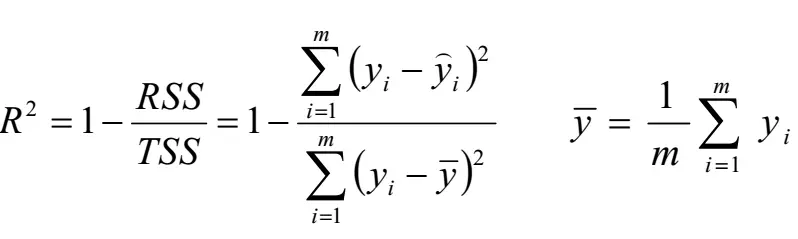
模型模拟的越好,越接近于1,函数调用`lr.score(x_test, y_test)`
- MSE和RMSE