文章
用词向量技术简单分析红楼梦人物关系
看机器能否读懂「宝黛」之间的爱情——用 n-gram 与 Word2Vec 分析红楼人物词向量。
前言:出于种种原因,总是不自觉把爱好和工作相互结合起来。每每感叹于曹雪芹构思的巧妙、语言的精炼、情节的感人……于是蹦出想法:看机器能否读懂「宝黛」之间的爱情。
数据处理
数据当然是伟大的《红楼梦》本身了,下载 txt 文件。
然后进行编码转化「utf-8」,分词,去除其中大量的空格和标点。然后有两种方法进行词向量的构建,分别是 n-gram 模型训练和 Word2Vec。
用 n-gram 生成词向量
把数据转化为如下格式:

也就是 N=2。上述操作代码如下:
with open("红楼梦.txt", encoding='utf-8') as f:
text = f.read()
temp = jieba.lcut(text)
words = []
for i in temp:
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'""《》]+|[+——!,。?、~@#¥%……&*():]+", "", i)
if len(i) > 0:
words.append(i)
trigrams = [([words[i], words[i + 1]], words[i + 2]) for i in range(len(words) - 2)]
print(trigrams[:3])然后建立词汇表:
vocab = set(words)
word_to_idx = {}
idx_to_word = {}
ids = 0
for w in words:
cnt = word_to_idx.get(w, [ids, 0])
if cnt[1] == 0:
ids += 1
cnt[1] += 1
word_to_idx[w] = cnt
idx_to_word[ids] = w然后就是模型构建和参数训练。模型结构如下:
- 输入层:embedding 层,先将输入单词的编号映射为 one hot 编码向量,然后通过线性层映射到词向量表示,输出为 embedding_dim。
- 线性层:从 embedding_dim 维度到 128 维度,然后经过非线性 ReLU 函数。
- 线性层:从 128 维度到单词表大小维度,然后 log softmax 函数,给出预测每个单词的概率。
具体代码可见:n-grama-and-wordvect-Analysis-of-the-text
迭代训练:
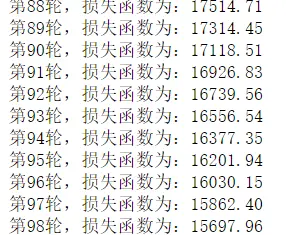
Word2Vec 进行模型训练
训练的时候需要把数据重新进行调整,变成句子进行输入,如下:
['因此', '大家', '议定', '每日', '轮流', '做', '晚饭', '之主']
['天天', '宰猪', '割羊', '屠鹅', '杀鸭', '好似', '临潼斗宝', '的', '一般', '都', '要', '卖弄', '自己', '家里', '的', '好', '厨役', '好', '烹调']
数据处理的代码如下:
f = open("红楼梦.txt", encoding='utf-8')
f = f.read().split("。")
lines = []
for line in f:
temp = jieba.lcut(line)
words = []
for i in temp:
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'""《》]+|[+——!,\- 。?、~@#¥%……&*():;'']+", "", i)
if len(i) > 0:
words.append(i)
if len(words) > 0:
lines.append(words)然后输入模型,将图像转化为二维空间进行展示:
model = Word2Vec(lines, size=20, window=2, min_count=0)
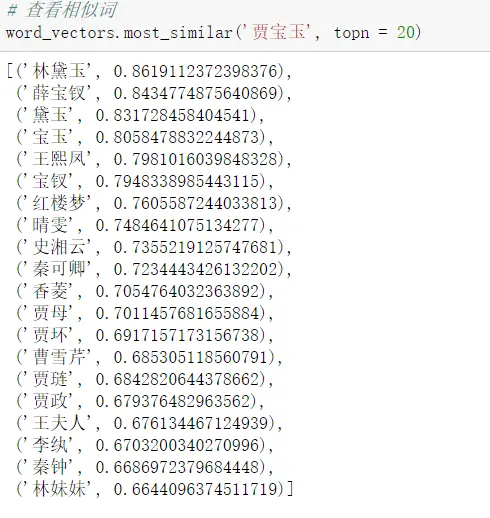
renwu = model.wv.most_similar('林黛玉', topn=20)
rawWordVec = []
word2ind = {}
for i, w in enumerate(model.wv.vocab):
rawWordVec.append(model[w])
word2ind[w] = i
rawWordVec = np.array(rawWordVec)
X_reduced = PCA(n_components=2).fit_transform(rawWordVec)然后绘制图像,并且展示几个特殊人物:贾宝玉、林黛玉、香菱、贾政、晴雯、妙玉、袭人、薛宝钗、王熙凤、平儿、贾母、探春。
fig = plt.figure(figsize=(15, 10))
ax = fig.gca()
ax.set_facecolor('black')
ax.plot(X_reduced[:, 0], X_reduced[:, 1], '.', markersize=1, alpha=0.3, color='white')
words = ['贾宝玉', '林黛玉', '香菱', '贾政', '晴雯', '妙玉', '袭人',
'薛宝钗', '王熙凤', '平儿', '贾母', '探春']
zhfont1 = matplotlib.font_manager.FontProperties(fname='./华文仿宋.ttf', size=16)
for w in words:
if w in word2ind:
ind = word2ind[w]
xy = X_reduced[ind]
plt.plot(xy[0], xy[1], '.', alpha=1, color='red')
plt.text(xy[0], xy[1], w, fontproperties=zhfont1, alpha=1, color='yellow')
plt.show()展示结果如下:

可以看到宝黛钗凤很相近,几乎都分不清他们的名字了。然后放大之后,震惊……

结论:原来机器也「读懂」了「宝黛」爱情。
补充:由于以上用的数据仅仅来自于《红楼梦》文本本身,如果有另外巨大的语料(微博、人民日报、上海热线、汽车之家等,包含 1366130 个词向量)训练出来结果如何呢?篇幅有限,直接上结果吧:
以上内容纯属个人娱乐,与君共勉,不喜请喷。