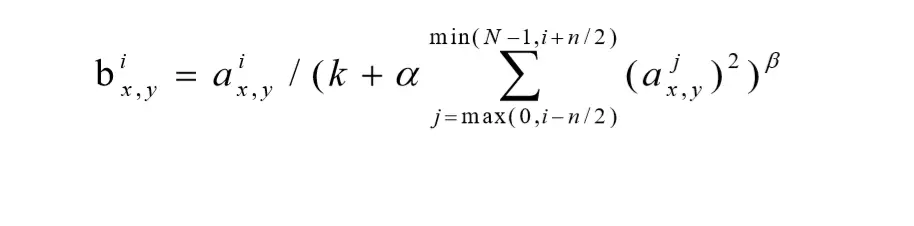文章
深度学习——CNN(1)
>-
前言:前面提到的神经元之间的连接都是全连接,当输入超多的时候全连接参数给定也会超多,计算太复杂,这样利用人观察事物的原理,既先抓住事物的主要特征(局部观看),而产生的cnn,不同和重点是加了卷积层(局部感知)和池化层(特征简化)。CNN的应用主要是在图像分类和物品识别等应用场景应用比较多
层级结构
-
数据输入层:Input Layer 和机器学习一样,需要对输入的数据需要进行预处理操作 常见3种数据预处理方式 1 去均值 将输入数据的各个维度中心化到0 2 归一化 将输入数据的各个维度的幅度归一化到同样的范围
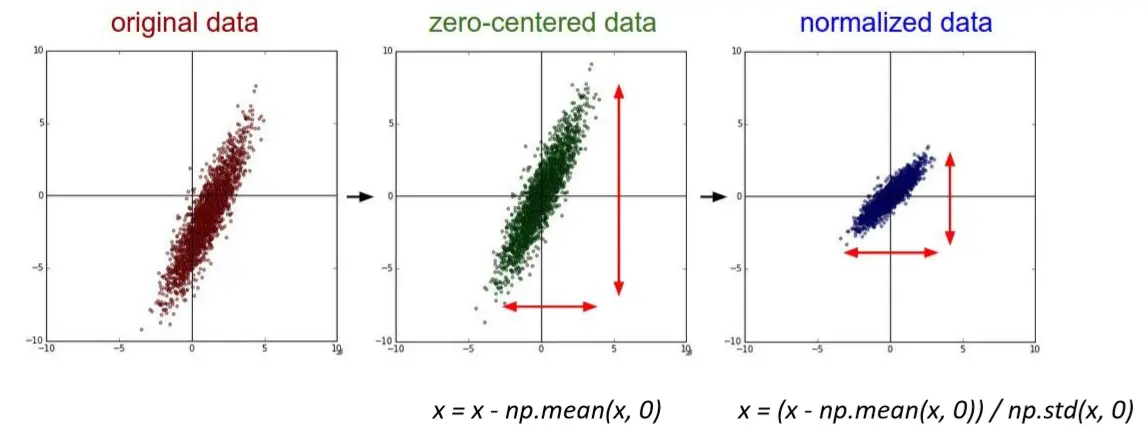 3 PCA/白化 用PCA降维(去掉特征与特征之间的相关性) 白化是在PCA的基础上,对转换后的数据每个特征轴上的幅度进行归一化
3 PCA/白化 用PCA降维(去掉特征与特征之间的相关性) 白化是在PCA的基础上,对转换后的数据每个特征轴上的幅度进行归一化 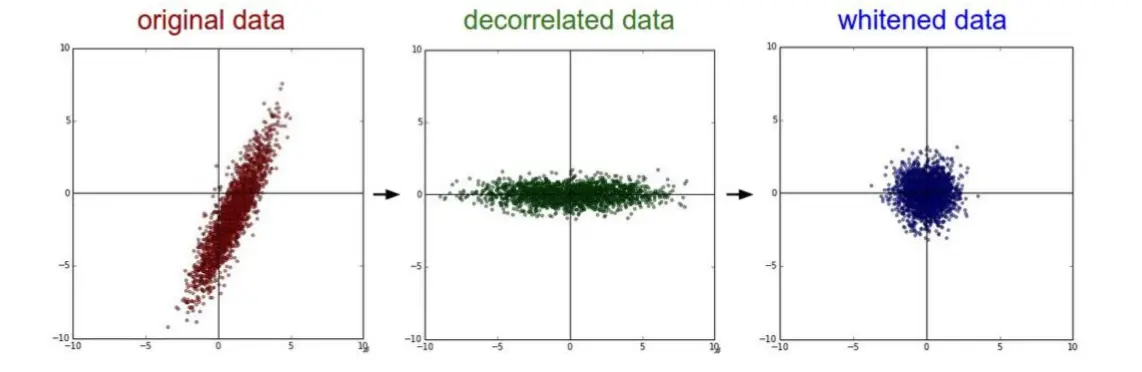 公式如下: 去 均 值x -= np.mean(x, axis=0) 计 算 协 方 差 cov = np.dot(x.T, x) / x.shape[0] 进 行 svd 分 解 u, s, v = np.linalg.svd(cov) xrot = np.dot(x, u) 计 算 pca x = np.dot(x, u[:, :2]) 白 化 x = xrot / np.sqrt(s + 1e-5) 实际上在卷积神经网络中,一般 并不会适用PCA和白化的操作,一般去均值和归一化使用的会比较多 卷积计算层:CONV Layer ReLU 人的大脑在识别图片的过程中,会由不同的皮质层处理不同方面的数据,比如: 颜色、形状、光暗等,然后将不同皮质层的处理结果进行合并映射操作,得出最 终的结果值,第一部分实质上是一个局部的观察结果,第二部分才是一个整体的结果合并。卷积层就是类似人脑识别物体的过程,先从一个方面来判断物体。 卷积计算层:CONV Layer 原理 局部关联:每个神经元看做一个filter 窗口(receptive field)滑动,filter对局部数据进行计算 相关概念 深度:depth 步长:stride 填充值:zero-padding CONV过程参考:http://cs231n.github.io/assets/conv-demo/index.html
公式如下: 去 均 值x -= np.mean(x, axis=0) 计 算 协 方 差 cov = np.dot(x.T, x) / x.shape[0] 进 行 svd 分 解 u, s, v = np.linalg.svd(cov) xrot = np.dot(x, u) 计 算 pca x = np.dot(x, u[:, :2]) 白 化 x = xrot / np.sqrt(s + 1e-5) 实际上在卷积神经网络中,一般 并不会适用PCA和白化的操作,一般去均值和归一化使用的会比较多 卷积计算层:CONV Layer ReLU 人的大脑在识别图片的过程中,会由不同的皮质层处理不同方面的数据,比如: 颜色、形状、光暗等,然后将不同皮质层的处理结果进行合并映射操作,得出最 终的结果值,第一部分实质上是一个局部的观察结果,第二部分才是一个整体的结果合并。卷积层就是类似人脑识别物体的过程,先从一个方面来判断物体。 卷积计算层:CONV Layer 原理 局部关联:每个神经元看做一个filter 窗口(receptive field)滑动,filter对局部数据进行计算 相关概念 深度:depth 步长:stride 填充值:zero-padding CONV过程参考:http://cs231n.github.io/assets/conv-demo/index.html 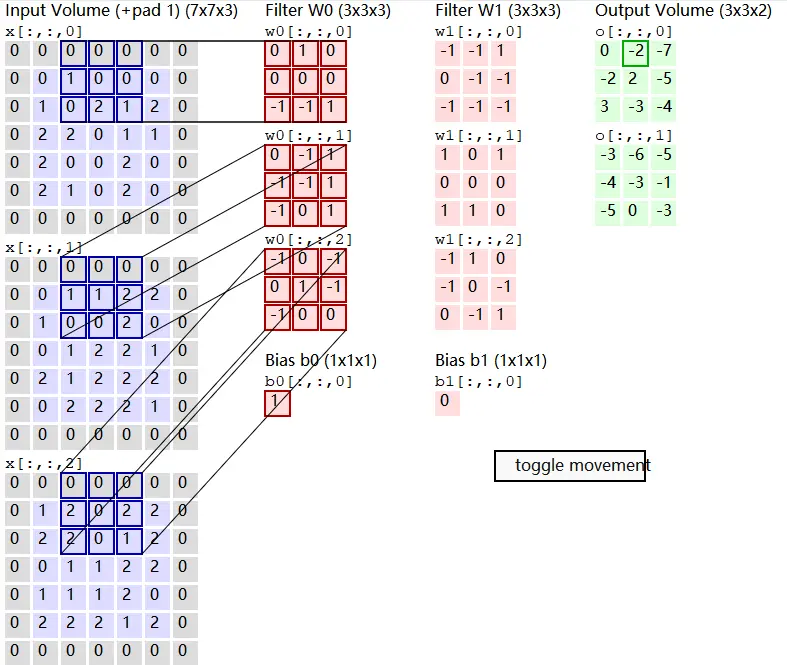 一个filter相当于前面提到的从一个方面来观察物体,通常情况下需要给定多个filter,形成一定深度的数据,如下图中的“depth”
一个filter相当于前面提到的从一个方面来观察物体,通常情况下需要给定多个filter,形成一定深度的数据,如下图中的“depth” 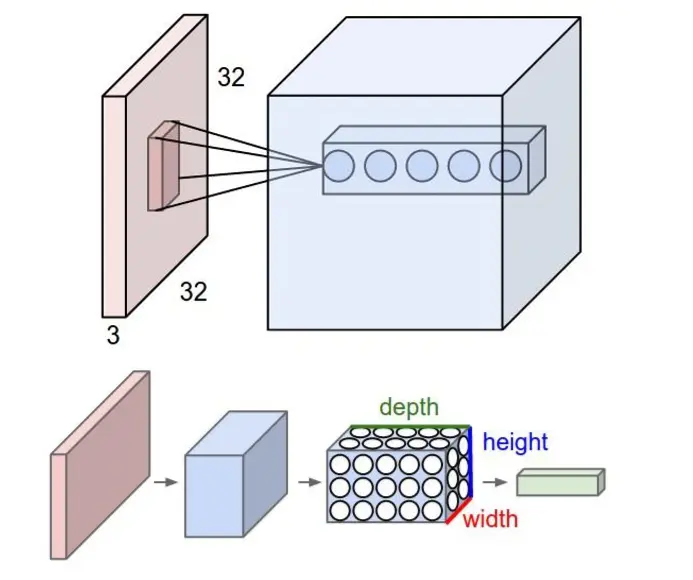 卷积层的特点 局部感知: 在进行计算的时候,将图片划分为一个个的区域进行计算/考虑; 参数共享机制:假设每个神经元连接数据窗的权重是固定的 滑动窗口重叠:降低窗口与窗口之间的边缘不平滑的特性。 固定每个神经元的连接权重,可以将神经元看成一个模板;也就是每个神经元只 关注一个特性 需要计算的权重个数会大大的减少 其实卷积的过程就是固定的窗口和filter做内积之后的求和 激励层:ReLU Incentive Layer 将卷积层的输出结果做一次非线性的映射, 也就是做一次“激活”
卷积层的特点 局部感知: 在进行计算的时候,将图片划分为一个个的区域进行计算/考虑; 参数共享机制:假设每个神经元连接数据窗的权重是固定的 滑动窗口重叠:降低窗口与窗口之间的边缘不平滑的特性。 固定每个神经元的连接权重,可以将神经元看成一个模板;也就是每个神经元只 关注一个特性 需要计算的权重个数会大大的减少 其实卷积的过程就是固定的窗口和filter做内积之后的求和 激励层:ReLU Incentive Layer 将卷积层的输出结果做一次非线性的映射, 也就是做一次“激活” 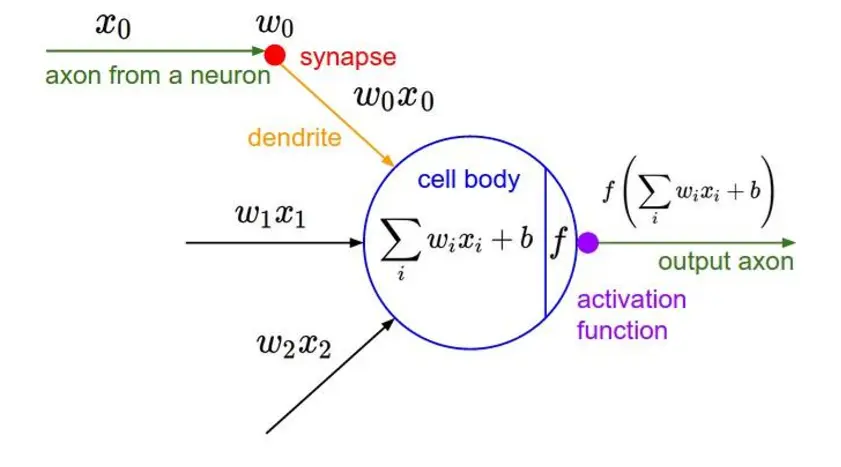 常用非线性映射函数
常用非线性映射函数 -
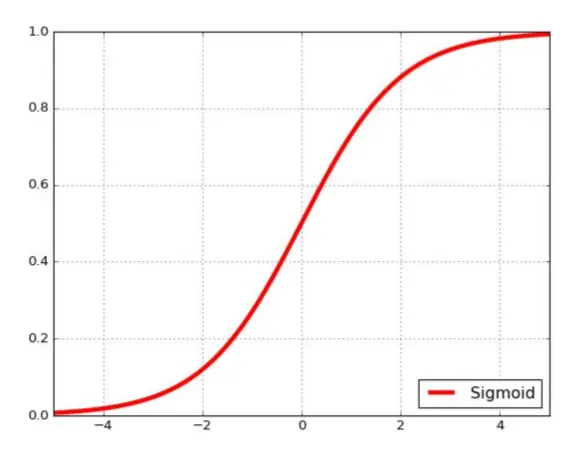
Sigmoid(S形函数) 这个函数经常见到,缺点是容易出现“死神经元”
 Tanh(双曲正切,双S形函数) 缺点和sigmoid类似,一般不用做cnn
Tanh(双曲正切,双S形函数) 缺点和sigmoid类似,一般不用做cnn 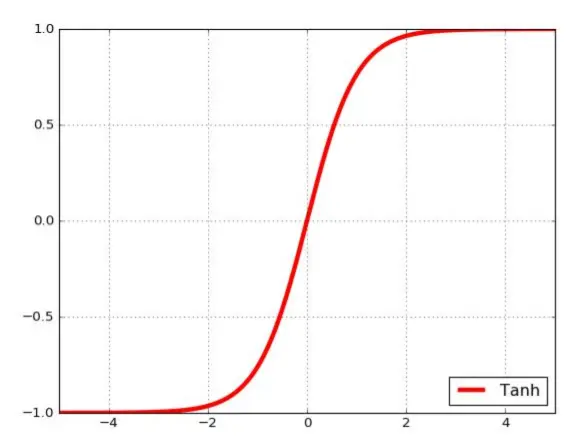 ReLU 对于输入的x以0为分界线,左侧的均为0,右侧的为 y=x这条直线。
ReLU 对于输入的x以0为分界线,左侧的均为0,右侧的为 y=x这条直线。 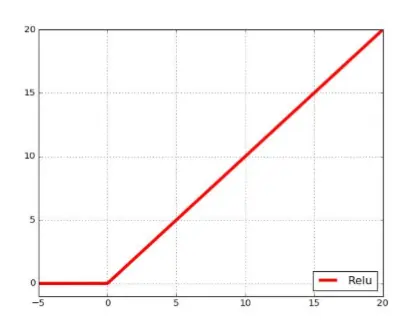 缺点: 没有边界,可以使用变种ReLU: min(max(0,x), 6) 比较脆弱,比较容易陷入出现”死神经元”的情况 • 解决方案:较小的学习率 优点: 相比于Sigmoid和Tanh,提升收敛速度 梯度求解公式简单,不会产生梯度消失和梯度爆炸。原理和人脑神经元类似
缺点: 没有边界,可以使用变种ReLU: min(max(0,x), 6) 比较脆弱,比较容易陷入出现”死神经元”的情况 • 解决方案:较小的学习率 优点: 相比于Sigmoid和Tanh,提升收敛速度 梯度求解公式简单,不会产生梯度消失和梯度爆炸。原理和人脑神经元类似 -
单侧抑制;
-
相对宽阔的兴奋边界;
-
稀疏激活性;
-
更快的收敛速度;
-
Leaky ReLU 在ReLU函数的基础上,对x≤0的部分进行修正;目的是为了解决ReLU激活函数中容易存在的”死神经元”情况的。
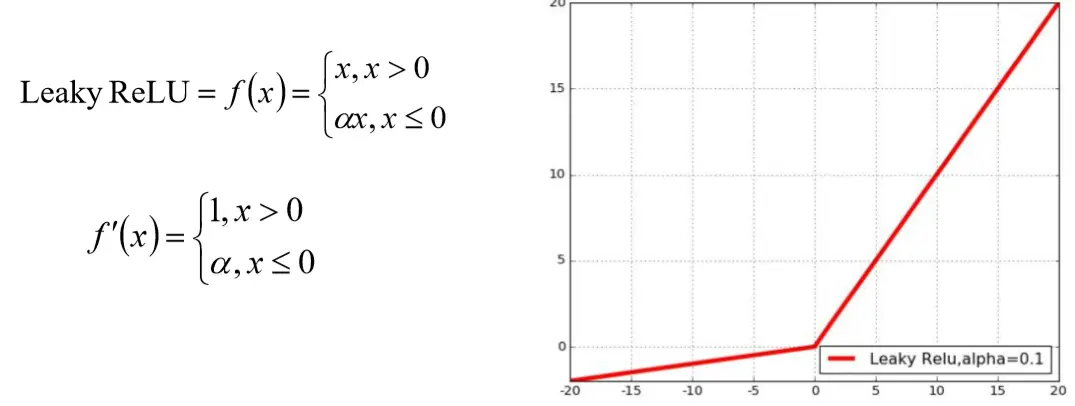 ELU Maxout 指数线性激活函数,同样属于对ReLU激活函数的x≤0部分的转换进行指数修正,而 不是和Leaky ReLU中的线性修正
ELU Maxout 指数线性激活函数,同样属于对ReLU激活函数的x≤0部分的转换进行指数修正,而 不是和Leaky ReLU中的线性修正 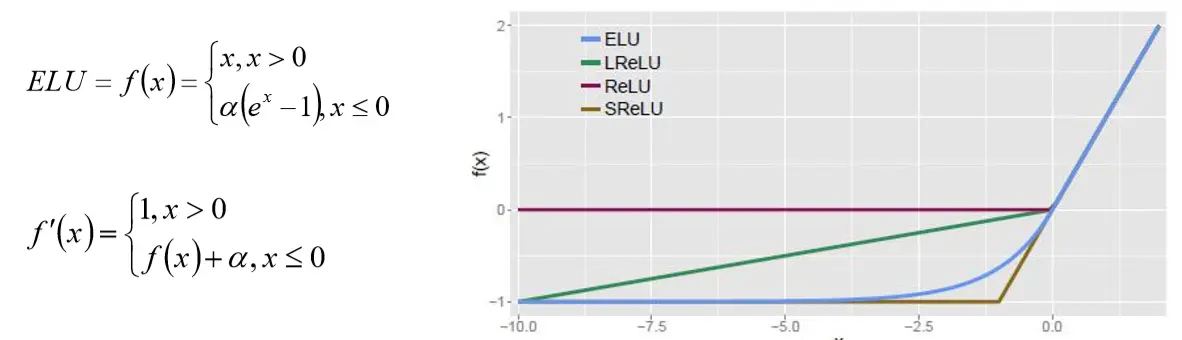 Maxout激活函数: 参考:https://arxiv.org/pdf/1302.4389.pdf 可以看作是在深度学习网络中加入一层激活函数层,包含一个参数k,拟合能力特别 强。 特殊在于:增加了k个神经元进行激活,然后输出激活值最大的值。 优点: 计算简单,不会出现神经元饱和的情况 不容易出现死神经元的情况 缺点: 参数double,计算量复杂了
Maxout激活函数: 参考:https://arxiv.org/pdf/1302.4389.pdf 可以看作是在深度学习网络中加入一层激活函数层,包含一个参数k,拟合能力特别 强。 特殊在于:增加了k个神经元进行激活,然后输出激活值最大的值。 优点: 计算简单,不会出现神经元饱和的情况 不容易出现死神经元的情况 缺点: 参数double,计算量复杂了 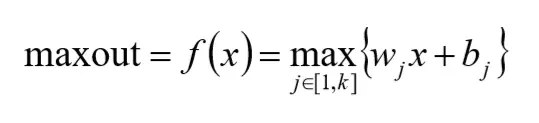
-
池化层:Pooling Layer 在连续的卷积层中间存在的就是池化层,主要功能是:通过逐步减小表征的空间 尺寸来减小参数量和网络中的计算;池化层在每个特征图上独立操作。使用池化 层可以压缩数据和参数的量,减小过拟合。
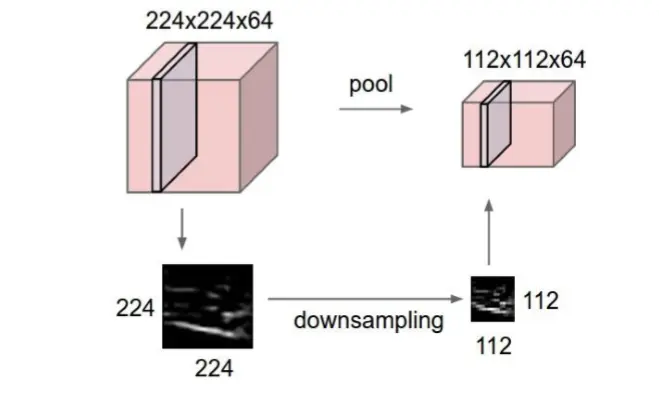 在池化层中,进行压缩减少特征数量的时候一般采用两种策略: Max Pooling:最大池化,一般采用该方式 Average Pooling:平均池化
在池化层中,进行压缩减少特征数量的时候一般采用两种策略: Max Pooling:最大池化,一般采用该方式 Average Pooling:平均池化 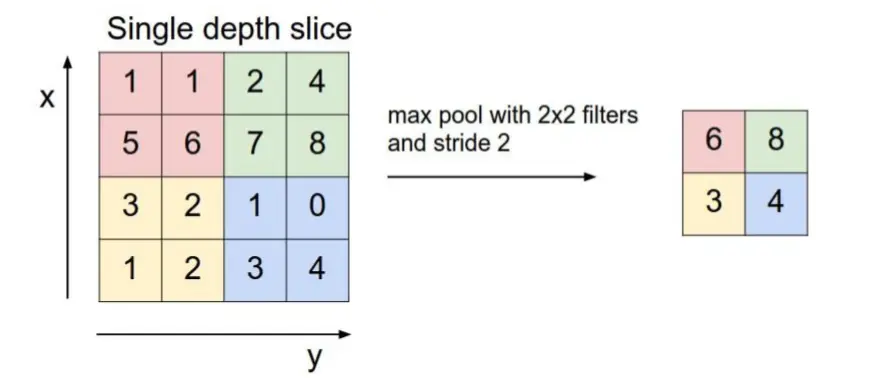
-
全连接层:FC Layer ,FC层中的神经元连接着之前层次的所有激活输出; 换一句话来讲的话,就是两层之间所有神经元都有权重连接;通常情况下,在 CNN中,FC层只会在尾部出现
CNN特点
优点 共享卷积核(共享参数),对高维数据的处理没有压力 无需选择特征属性,只要训练好权重,即可得到特征值 深层次的网络抽取图像信息比较丰富,表达效果好 缺点 需要调参,需要大量样本,训练迭代次数比较多,最好使用GPU训练 物理含义不明确,从每层输出中很难看出含义来
卷积神经网络-参数初始化
在卷积神经网络中,可以看到神经元之间的连接是通过权重w以及偏置b实现的。 在具体的神经网络之前,我们还有一个任务需要做,那就是初始化参数 权重的初始化 一般方式: 很小的随机数(对于多层深度神经网络,太小的值会导致回传的梯度非常小), 一般随机数是服从均值为0,方差未知(建议:2/n, n为权重数量)的高斯分布随机数列。 错误方式:全部初始化为0,全部设置为0,在反向传播的时候是一样的梯度值,那么这 个网络的权重是没有办法差异化的,也就没有办法学习到东西。 偏置项的初始化 一般直接设置为0,在存在ReLU激活函数的网络中,也可以考虑设置为一个很小的数字
卷积神经网络过拟合解决办法
当层次增加或者神经元数目增加的时候非常容易出现过拟合 Regularization:正则化,通过降低模型的复杂度,通过在cost函数上添加 一个正则项的方式来降低overfitting,主要有L1和L2两种方式 Dropout:通过随机删除神经网络中的神经元来解决overfitting问题,在每 次迭代的时候,只使用部分神经元训练模型获取W和d的值。 每次丢掉一半左右的隐 藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依 赖性,即每个神经元不能依赖于某几个其它的神经元(指层与层之间相连接的神经 元),使神经网络更加能学习到与其它神经元之间的更加健壮robust(鲁棒性)的特征
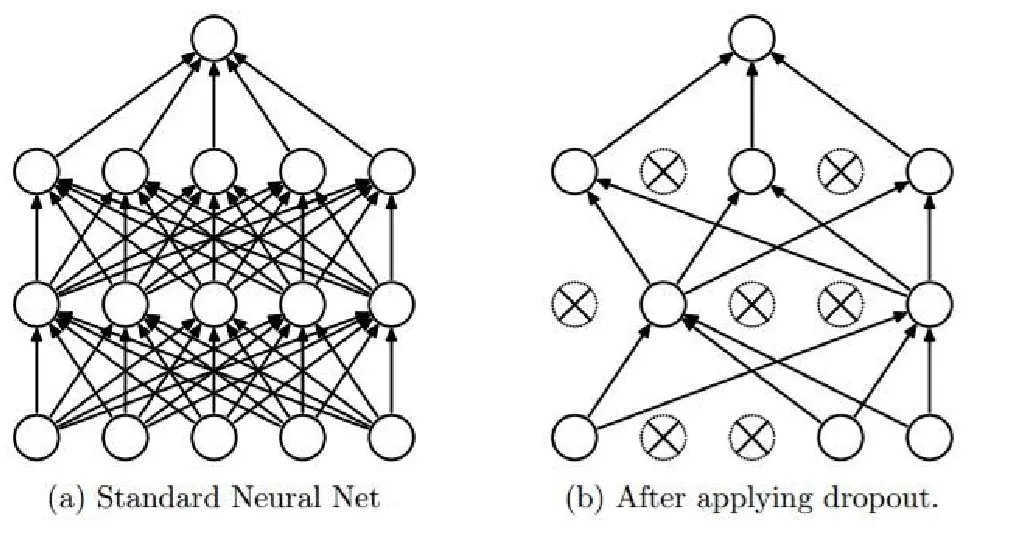
局部响应归一化( LRN )
局部响应归一化层的建立是模仿生物神经系统的临近抑制机制,对局部神经元的活动创 建竞争机制,使得局部响应比较大的值相对更大,这样更能凸显需要的特征,提高模型泛 化能力。 LRN一般是在激活、池化后进行的一中处理方法。用 表示经过激活函数后的输 出值,对于第j 个卷积核经过激活函数输出的神经元激活值 ,选取临近的n个卷积核卷 积后的输出值,将它们在同一个位置上卷积后激活函数的输出值进行求和。其中(x,y) 就代 表特征层的坐标位置,i,j就代表不同的卷积核,N为总卷积核数目,k ,a, 和β都是超参数,由 验证数据集决定,一般取k =2,a =10-4 , β = 0.75,具体的如下: